Search Query Language
May 22, 2025
Netlas search tools are based on a simple query language called the Apache Lucene query syntax. Apache Lucene is a powerful text search engine library used under the hood by many well-known tools, including Apache Solr, Elasticsearch, Kibana, and others.
Fields and Search Terms
A basic search query includes two parts, separated by a colon:
- a document field – where to search
- a search term – what to search for
Example of a simple search query:
This means: "Find documents where the host field has the value google.com".
Be careful with spaces
Note that there should be no spaces between the field, the colon, and the search term. In Lucene, spaces act as separators to combine multiple search conditions.
Default Fields
If no field is specified, the search is performed on the default fields. Try this query in the Responses Search tool:
Each data collection defines its own set of default fields1.
Mapping
All searchable fields are listed in the mapping. Each data collection has its own mapping. You can click on a field to insert it into the search string.
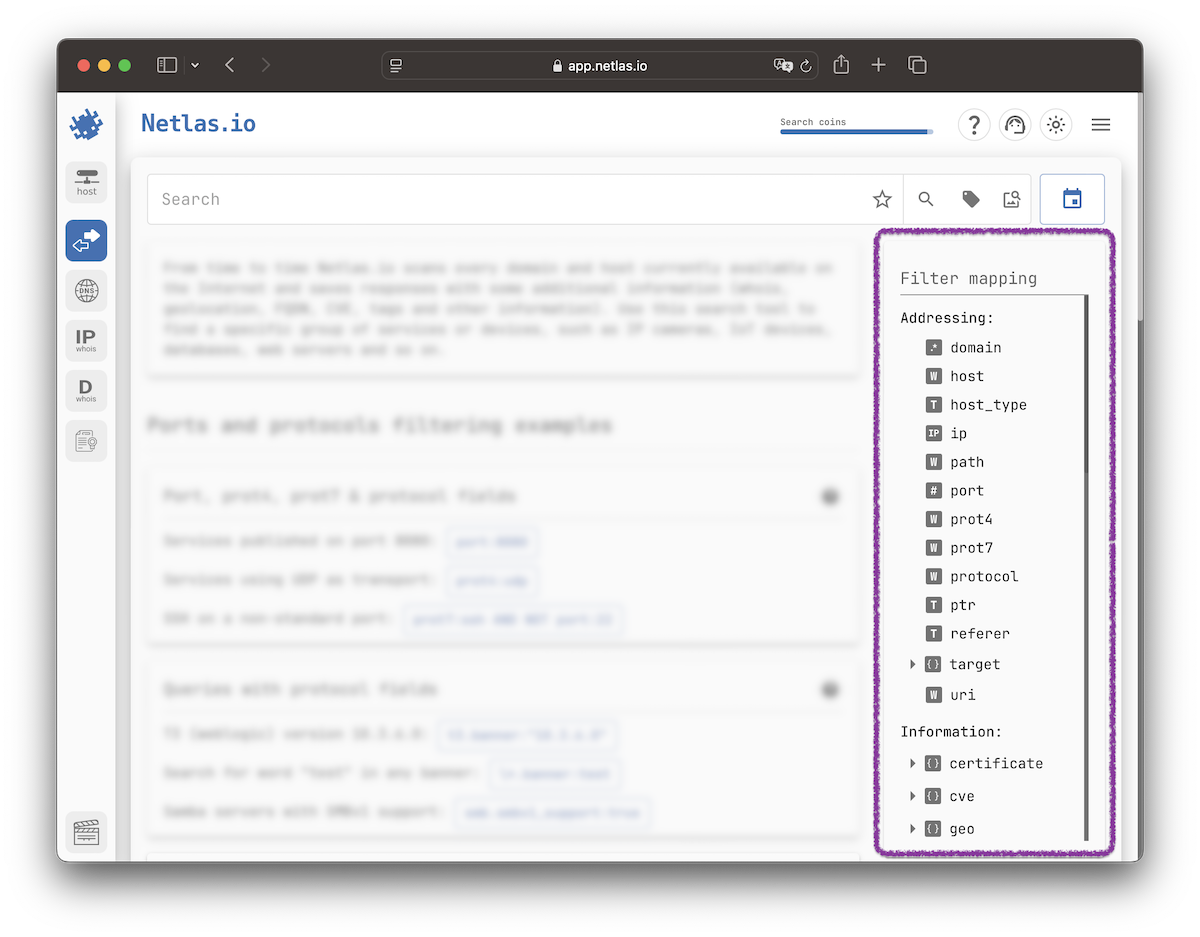
Some fields contain subfields. Subfields are referenced using dot notation: field.subfield.
For example, in the Responses Search, the geo field contains the subfield country:
Field Reference
See the Field Reference articles for details on key fields, value options, and example queries.
Data Types
Each field in the mapping has an icon representing its type. Hover over the icon to see the type name.
The field type determines how it can be queried.
| Type | Description | Operations |
|---|---|---|
| BINARY | Base64-encoded binary values. Not searchable directly. | — |
| BOOLEAN | Logical values: true or false. Example: smb.smbv1_support:true |
✓ Match |
| DATE | ISO 8601 date/time format. Examples: • scan_date:2025-03-21• http.favicon.last_modified:<=2023-12-31• @timestamp:[now-7d TO now] |
✓ Match ✓ Range ✓ Relative |
| DOUBLE FLOAT SCALED_FLOAT INTEGER LONG SHORT |
Numeric types. Examples: • http.status_code:200• http.status_code:[200 TO 299]• port:<1000• cve.base_score:>9.5 |
✓ Match ✓ Range |
| IP | IPv4 and IPv6 addresses. Examples: • ip:1.1.1.1• ip:[1.1.1.0 TO 1.1.1.255]• ip:"1.1.0.0/16" |
✓ Match ✓ Range ✓ CIDR |
| IP_RANGE | IP ranges. Supports direct match and filtering. Examples: • ip:1.1.1.1• ip:[1.1.1.1 TO 1.1.1.5] |
✓ Match ✓ Range |
| KEYWORD WILDCARD |
Exact-match strings, case-sensitive, no tokenization. Examples: • host:app.netlas.io• domain:*.gov |
✓ Match ✓ Wildcard ✓ Regex ✓ Fuzzy |
| TEXT | Full-text searchable fields with tokenization. Example: http.body:password |
✓ Match ✓ Wildcard ✓ Regex ✓ Fuzzy ✓ Exact Match |
| VERSION | Semantic version format. Example: tag.php.version:<=5.3.3 |
✓ Match ✓ Range |
Text Fields
The TEXT type is designed for full-text search across large volumes of content, returning all relevant results rather than just exact matches.
Fields of type TEXT store data in a tokenized and normalized form. This means that punctuation, special characters, and service symbols are ignored during search. Searches are also case-insensitive and tolerant to word forms — for example, singular and plural are treated as equivalent.
Let’s look at a couple of examples to understand the pros and cons of tokenization:
This query will match documents with titles like:index ofIndex ofIndex of:INDEX OFINDEX ofindex /of
Another example:
Matches include:
Stephen William HAWKING- URLs such as
http://some-blog.com/label/Stephen%20Hawking/ - etc.
The difference between quoted and unquoted multi-word searches is explained in Exact Match.
Special character search in http.body
The http.body field is stored as TEXT, so it cannot be used to search for special characters like <html> or </body> due to tokenization.
Keyword Fields
For fields where exact matching is essential, the KEYWORD type is used. These fields are not analyzed, meaning they are stored and searched as-is, without tokenization.
Example – the following query in the DNS Search will likely return no results:
This is because KEYWORD fields are case-sensitive. The correct version is:
If a domain field were stored as TEXT, a search like domain:netlas.io might match:
app.netlas.ionetlas.io-io-ho.com
That’s why exact match fields must be of type KEYWORD.
Need an exact match on a TEXT field?
Use the .keyword subfield when available:
This only works for fields up to 256 characters long (e.g., not http.body).
TEXT vs KEYWORD
| Feature | TEXT | KEYWORD |
|---|---|---|
| Matching Type | Analyzed | Not analyzed |
| Case Sensitivity | Case-insensitive | Case-sensitive |
| Punctuation Handling | Ignored | Preserved |
| Special Characters | Ignored during search | Must be matched exactly |
| Word Forms (e.g., plural) | Treated as equivalent | Must match exactly |
Subfield .keyword |
Available for short fields (≤ 256 chars) | Not applicable |
Search Operators
Apache Lucene supports several powerful operators, including range queries, fuzzy searches, wildcards, and regular expressions.
Range Search
DATE ALL NUMERIC IP IP_RANGE VERSION
You can specify ranges for date and numeric fields using the [ TO ] syntax or use one-sided comparisons with <, >, <=, or >=.
Apache Lucene supports inclusive and exclusive range syntax:
| Syntax | Meaning |
|---|---|
[a TO b] |
Inclusive (≥ a and ≤ b) |
{a TO b} |
Exclusive (> a and < b) |
[a TO b} |
Inclusive lower, exclusive upper (≥ a and < b) |
{a TO b] |
Exclusive lower, inclusive upper (> a and ≤ b) |
CIDR-based IP Filtering
IP
Netlas supports searching for IP addresses within subnets using CIDR notation. This allows you to match entire IP ranges without specifying individual addresses.
Example — match any IP in the 1.1.0.0/16 subnet:
/ must be escaped:
Relative Date Queries
DATE
Relative queries for dates allow you to filter documents based on time relative to the current moment (now).
From the last 24 hours:
From the past 7 days up to now:
From the beginning of today to now:
Fuzzy Search
TEXT KEYWORD WILDCARD
Use fuzzy queries with the ~ operator to find terms with similar spelling or slight variations. This is useful for catching typos, alternative word forms, or minor differences in domains or names.
You can specify the distance (edit distance) with a number after the ~. The supported values are 1 or 2 (default is 2).
Wildcards
TEXT WILDCARD KEYWORD
Use the asterisk (*) and question mark (?) operators to match any sequence of characters or a single character, respectively.
Wildcards are commonly used with KEYWORD and WILDCARD fields to perform partial matches within field values.
For example, this query will return domains that start with the word voip:
Another example — subdomain search:
When using wildcards within a TEXT field, the wildcard should replace part of a search term, not span across multiple words.
For example:
This query can match titles such as:
My WordPress BlogWord of Mouth BlogWords Of My Life | Blog
You can also use an asterisk to match any field or subfield name, but in this case, it must be escaped with a backslash (\). The query below returns results from any protocol where the banner contains the word email:
Wildcards * and ? do not function inside quoted phrases
Any special character placed inside quotes is treated as a literal character, not as an operator, because quotes are used as an exact match operator.
So the query "word* blog" is interpreted as:
- A phrase with the tokens
wordandblogin a TEXT field (the*is discarded during analysis) - An exact literal string
word* blogin a KEYWORD field
Regex
TEXT KEYWORD WILDCARD
Regular expression patterns can be embedded in the query string by wrapping them in forward slashes (/).
Netlas uses Lucene’s regular expression engine, which does not support PCRE (Perl-Compatible Regular Expressions), but it does implement most standard regex operators.
Exact Match
TEXT
Quoted phrases are used in Apache Lucene to perform exact match searches.
An exact phrase search within a TEXT field matches tokens in the exact order, after analysis. For example:
This query will match various forms like:
Wordpress | Blogwordpress-blogWordPress Blog
However, it will not match phrases that include words between the terms, such as:
WordPress | My Awesome BlogBlog about WordPress
This is because TEXT fields are analyzed — spaces, punctuation, and case are normalized, but quoted phrases require the tokens to appear in the exact same sequence.
Quotes are also commonly used with KEYWORD fields to include spaces or special characters without escaping.
For example, the two queries below are equivalent, but the first is easier to read:
Logical Operators
Use AND, OR, and NOT operators (which can also be written as &&, ||, and !) to build complex search queries:
The default operator is AND. It is applied when you combining search queries without specifying any operator. The following two queries return the same results:
Use brackets to combine search terms:
Use NOT (or !) to exclude documents that match a specific search condition:
Note that the ! operator must not be preceded by a space.
Existence Check
The asterisk (*) is commonly used as an existence operator — it matches any value in a field.
The following query returns documents that contain the http.header.location field:
When used with the ! operator (or NOT), it acts as a "not exists" operator.
For example, the following query returns all web pages that do not have a title:
Search Tips
It may seem a little confusing at first to write search queries. Try learning from examples:
-
Find some examples right in the app under the search bar.
-
More examples are available in the Netlas Dorks repository.
-
Netlas and feeds are also good sources of relevant query examples.
-
Default fields for each data collection are described in the relevant Field Reference article. ↩